…and why do I need to worry about it?

This is the first article in a series exploring the evolution of search, and how SME’s can benefit from it. In this post we’re exploring the term ‘Semantic Search’ and understanding what difference it makes to search results. Gaining this understanding is important as it will help you develop your Authorship strategy over the coming weeks.
Better search
Put simply, Semantic Search is a means of improving the understanding of the intent of the person making an online search, and in doing so provide more accurate search results.
One issue with web searches ever since Google started indexing as much of the web as possible, has been producing highly relevant results. Consider, for instance, the fact that the verb run has over 600 different meanings listed in the Oxford English Dictionary!
Whilst run, on its own, may not be a very common search term; there are many other words in English (and no doubt plenty in other languages too) that have different meanings depending on the context in which they are used.
For example, someone typing the word Giant into the search box may possibly be looking for…
-
Giant bicycles
-
Giant, the 1956 film
-
Giant Food Stores, of Maryland, USA
-
Giant Supermarkets, in Malaysia
-
The San Francisco Giants baseball team
Without knowing the context of the search, a search engine has to either present all the results, of find some way of asking the searcher which one they were referring to. Most browsers these days will offer a combination of the two approaches, showing results from all contexts, but allowing the searcher to select the appropriate one to filter the results.
But that’s not all!
As we’ve seen, one-word queries can be pretty ambiguous. Often, adding extra words to a query makes it less so, but there is still plenty of scope for misinterpretation.
For instance, if I were to type “cork pizza” would I be looking for a rather chewy Italian meal, or for a restaurant in the Irish city?
Determining context
The holy grail for search engines, of course, is to just present the more accurate results without having to ask for extra information. There are a number of techniques used, either separately or in combination, to try to achieve this.
Understanding the page context
Firstly, when indexing the web, a search engine needs to understand as best it can the context of each page. So, using our example above, if you write a blog post about Giant, then telling the search engine that the context is cycling helps enormously.
HTML5, the latest version of the venerable markup language that powers the World Wide Web, has been extended to allow for just such information to be added to web pages. Going into details about HTML5 and the specifics of this markup is outside the scope of this article, but Ana Hoffman has covered it in depth, with videos, already. So if you want to find out more then that’s a great resource.
Understanding the query
Knowing more is known about pages is all very well, but great search is about matching the query to the right page. In order to do that, better understanding of the query helps. As I mentioned above, the opportunities to misinterpret a query are many, and it’s still not perfect.
Search history
However, significant progress is being made, as this recent video of voice search on a mobile demonstrates.
What are we seeing here? Quite simply, a more intelligent search! Google is taking the context in which a series of search occur, and applying that to reduce ambiguity.
So in the video a question is asked about Thanksgiving, and the response describes when that occurs in USA. The next question is simply “I meant the Canadian one”, and this is used to refine the original search.
Of course this is using Google Voice Search, but the underlying technology and intelligence is used regardless of the interface.
What we are seeing is the history of searches in that particular interaction being used to infer the context of the conversation. It can be seen as a step towards passing the Turing Test.
Understanding the person
Taking this one simple, logical step further, what if our search engine knows about the entire search history of the person making the search. What if they also know other relevant information, such as their favourite football team?
In fact, that’s where Google+ steps in. By giving people an incentive to be logged in when making searches, and to fill out a pretty comprehensive profile, Google can make their searches more relevant to them.
For instance, as a Liverpool FC fan, if I search for ‘Liverpool’ I am more likely to see LFC-related results than someone who has expressed an interest in the history of slavery (Liverpool’s slavery museum is worth a visit if this is your thing).
Friends and family
As well as assuming I am most likely to be searching for LFC information, Google also knows the people that I interact with on Google+. This is pretty important in refining search results.
To understand why, you simply need to consider how you might have searched for stuff before computers and the internet arrived on the scene. If, say, you were looking for a plumber to do some work on your house, you would probably have done a couple of things:
-
looked in the yellow pages
-
looked at local newspaper adverts
-
looked in local shop windows at postcard ads
-
sought personal recommendations from friends and family
In each of those processes you are refining your search based on a couple of criteria…distance and expertise (or at least enough expertise to satisfy people you know and trust. Of all these criteria, a personal recommendation has usually been most valuable.
Personalising search
That personal recommendation has been difficult to replicate in search. Indeed, other online services have cropped up to fill that gap, such as Checkatrade in the UK.
But now that the other pieces of the puzzle are in place, Google are starting to build personalisation into search, giving you an online equivalent of your cousin John recommending a really good plumber.
The most visible manifestation of this is Authorship…where a search result appears with the page/article author’s image next to it.
There are a couple of interesting results from the introduction of these “rich snippets” to search results.
- They throw out of the window the rules on what percentage of clicks a #1 result on Google can expect.
Before authorship, it was a pretty hard and fast rule that ranking #1 gave you about 40% of clicks for a search. But consider the eye tracking heatmap below…
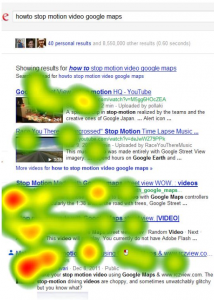
Now we see that the first rich snippet is really drawing the eye. Even more so than the youtube results, showing that a face works really well in this context.
(incidentally, this may be why Google really, really want you to have a headshot as your profile image…its in your interest!). - The search rankings are personalised somewhat so that results from people within your Google+ circles are boosted.
Note: A little care needs to be taken with this statement as there is still discussion over what types of search are affected and how big the impact is. http://www.conductor.com/blog/2013/07/google-in-the-serps-increasing-authorship-adoption-high-data/
However, there is certainly a difference when searching anonymously against searching whilst logged in to Google+.
Conclusion
In summary, semantic search is all about the delivery more accurate search results through better understanding of the context of the request, and knowledge of the interests and social circles of the requester.
The next article will start to look at how you, as a business, can position yourself to benefit from semantic search. We’ll also elaborate on why this levels the playing field for SEO, allowing you to compete with companies spending thousands.
Recent comments